I have been investigating the use of logistic regression to model image pixel data. Now I want to take a look at the use of neural networks. In this post I am going to build the simplest possible neural network and compare it against a simple logistic regression.
Tag Archives: Hieroglyphics
Stepping Carefully
In this post I will continue with my so-called hieroglyphics project. This project uses a set of image data that describes handwritten characters. The dataset is frequently used to evaluate machine-learning algorithms. I’m using the dataset to explore a variety of modelling techniques within JMP.
In my last post I used a script to incrementally add terms to my model so that I could explore the performance of the model with increasing complexity. But the order in which I added the terms was based on a heuristic and it wasn’t necessarily optimal. So in this post I want to explore using stepwise regression.
Logistic Regression pt. 2
Logistic Regression pt.1
In a recent post I created a table that contained two classes of data: images that represent either the handwritten digit ‘5’ or the digit ‘6’. In this post I’ll model the data using logistic regression. I will also take the opportunity to look at the role of training and test datasets, and to highlight the distinction between testing and validation.
Fives and Sixes
In my last post I was able to successfully re-orient a set of pixel data to reconstruct images of handwritten digits. SInce version 12 of JMP we have been able to create expression table columns that can contain images. That’s a logical location to store my newly revealed images:
Flippin’ Images
My last post contained a picture of a window that contained a grid of images. This was a randomly generated array of images based on an extract from the MNIST dataset. This database contains over 60,000 samples of handwritten digits.
However, my pixel data was disoriented and the images looked more like hieroglyphs. Fortunately JMP understands an image as an ‘object’, and allows a variety of transformations to be applied to it, including flipping and rotating.
Hieroglyphics?
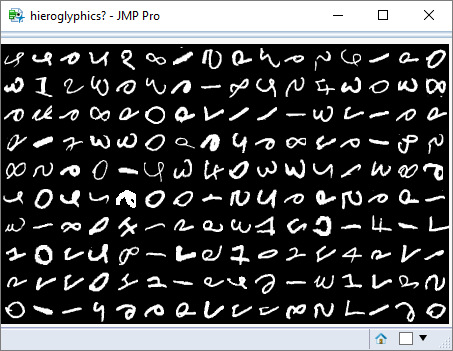
What is this? Any guesses?
(to be continued… )