One of my favourite ways of visualising data is with the use of a tree map.

Tree maps were developed in the 1990s by Ben Shneiderman at the University of Maryland to address the need for “space-constrained
visualisation hierarchies”.
The original motivation was to look at the hierarchical tree-structure of files on a PC hard drive and visualise the utilisation level across different folders – I think his basic problem was that his students were using too much disk space!
A tree map is like a bar chart folded over into a second dimension – bars become tiles that are organised in a way that maximises the available space for the graphic. The area of the tile represents a chosen statistic.
Here is an example of a tree map applied to the Movies data table available in the JMP sample data:

Let’s see what insights are contained within this visualisation:
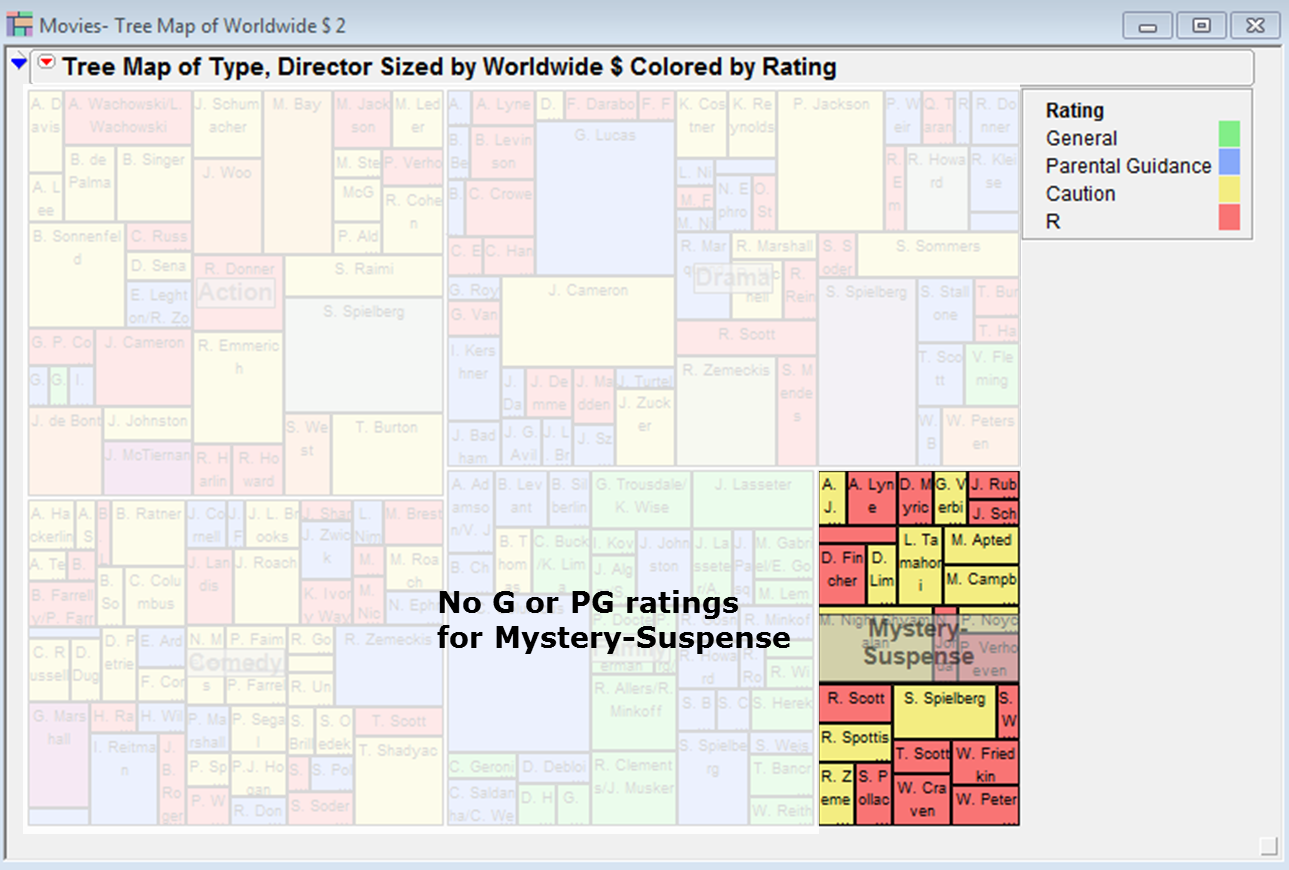
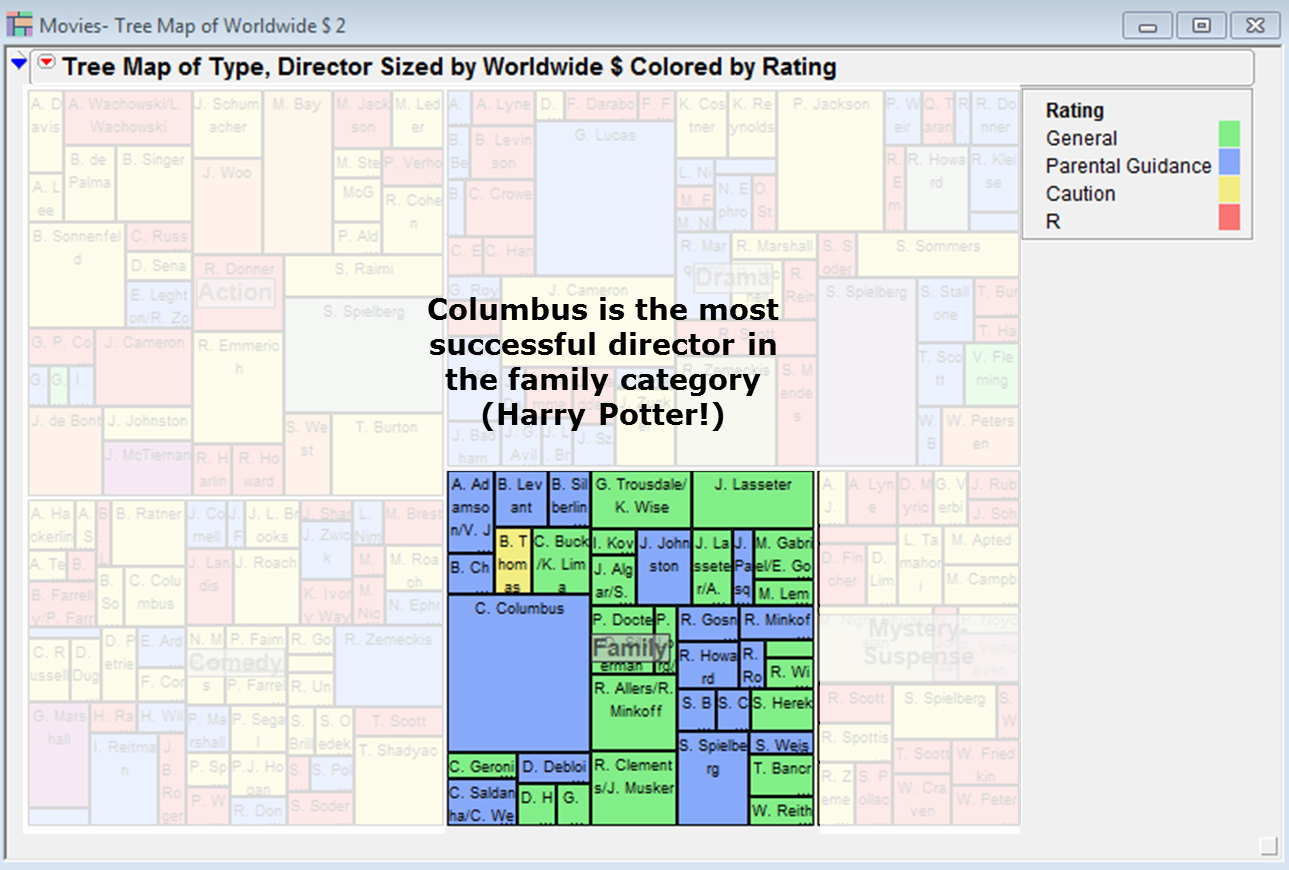

As with all forms of visualisation, the suitability of the method depends on the nature of the available data. Sometimes we have the tight type of data but it’s just plain disappointing when we use a tree map to identify patterns of interest. The example below is based on a process capability statistic Cpk across numerous process variables:

There are two problems with this graphic. First, most of the tiles are of similar size – I need large variations for my eye to pick out patterns. Second, the visualisation hides information that is potentially most useful: the small tiles show where there is a problem with process capability yet it is almost impossible to read their labels. I can address both of these issues with a simple transformation to the Cpk statistic. I want to magnify differences in values and place the greatest emphasis on the small values of Cpk; so I create a column formula which is the inverse of the square of Cpk:
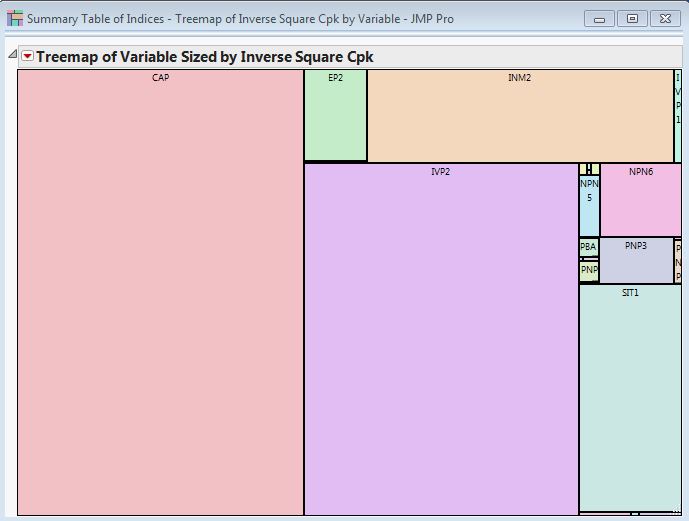
Now I can clearly see that the worst performing variables are CAP and IVP2, followed by INM2 and SIT1.