In my previous post I introduced the sample data table Pet Survey. I created a column formula to classify each respondent to determine whether they owned a cat, a dog, or both. In this simple example, there were signs of the problems that arise when processing unstructured text data. My classification of “dog” missed out responses referring to huskies; my classification of “cat” incorrectly included references to cattle. I looked at the Text Explorer platform and focused on the output contained in the lists of terms and phrases. In this post I want to focus on workflow: using the functionality within Text Explorer platform to gain meaningful insights into my data, and to answer specific questions.
This is the default output that I have from the Text Explorer platform working with the sample data Pet Survey.
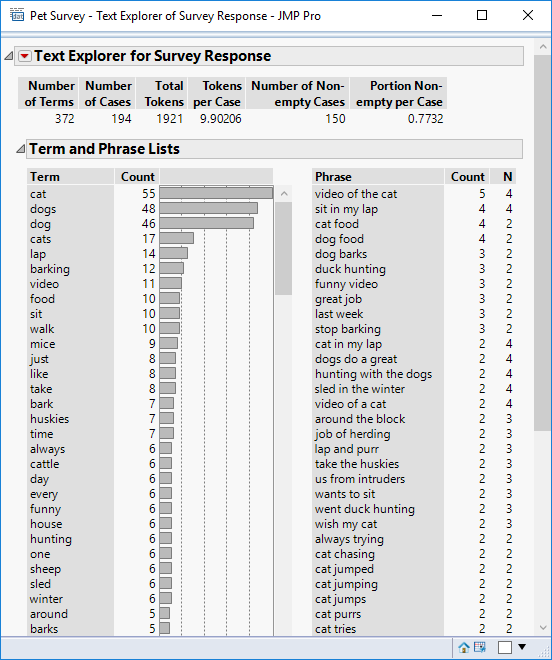
Let’s try and use the platform to determine whether a respondent owns a cat or a dog. To do this I want to focus on the terms. Really I’m only interested in “cat” and “dog”, but I have to take into account possible variations.
Stem Rules
Common variations of a word share the same stem. The most obvious example is “cat” and “cats”. I would like to collapse both of these words into a single term “cat”.
Stemming is the process of combining words that start with the same sequence of characters (the stem).
When the platform is launched there is an option to specify stem rules: Stem For Combining and Stem All Terms. The default is No Stemming.
The above output is based on the default option of no stemming. But I can change the option from the red triangle hotspot:
Term Options> Stemming
I want to stem the terms for the purpose of combining the terms so I can select the option Stem For Combining. The output now changes:
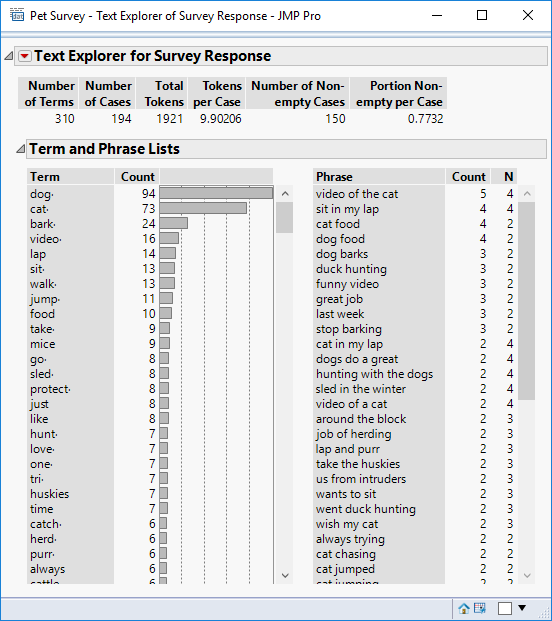 Whereas I had 46 counts of dog and 48 counts of dogs I now have 94 counts of the stem dog.
Whereas I had 46 counts of dog and 48 counts of dogs I now have 94 counts of the stem dog.
Another good example is the stem bark; this includes 7 instances of “bark”, 12 instances of “barking” and 5 instances of “barks”.
Recoding
The effect of stemming rules is to allow multiple tokens to be combined into a single term. Sometimes we want to combine terms even though they don’t share a common stem. In this data, I want to place “huskies” with the “dog” term. I can achieve that by recoding. Note that unlike column recoding, this functionality is local to the Text Explorer platform. To activate recoding I select the option from the red triangle hotspot:
Term Options> Manage Recodes
Selecting this option launches a window for managing recodes:
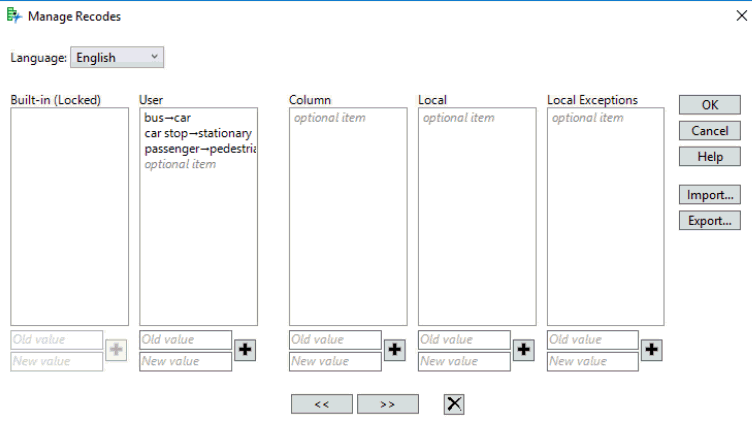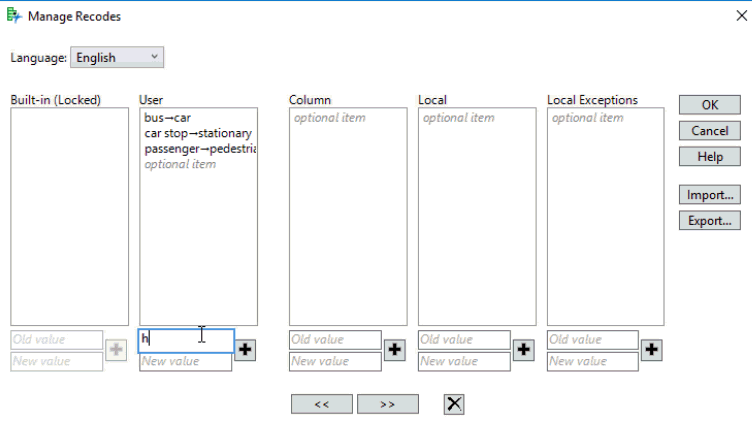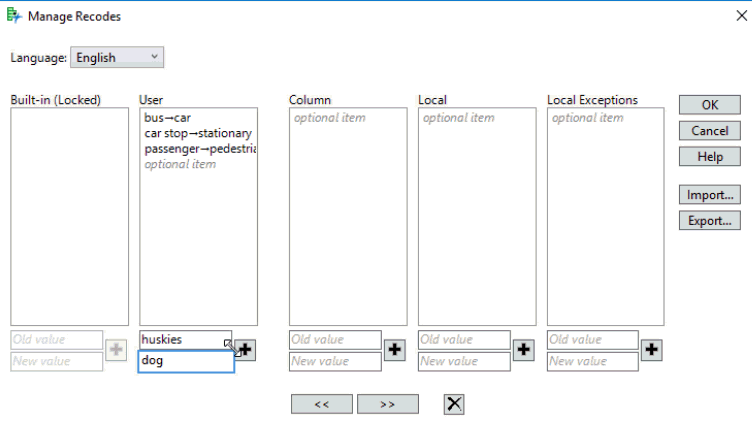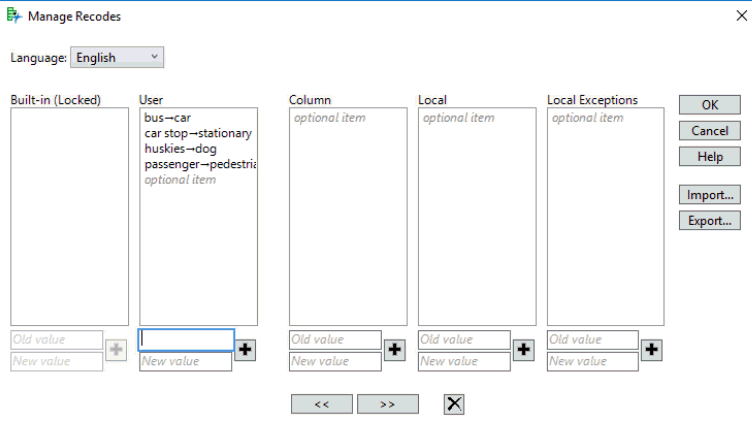
With this recoding 7 instances of “huskies” are now combined with the 94 “dog” terms.
[technical note: JMP applies recoding rules before stem rules]
Classifying the Respondents
The purpose of generating the “cat” and “dog” terms was to help determine whether a particular respondent was the owner of a cat or dog.
As you would expect from JMP, the reports within the Text Explorer platform are live-linked to the source data table. That means you can right-click on the dog term, choose Select Rows and all associated rows in the table are selected. Rather than selecting the rows I want to generate an indicator column (or a formula) that indicates the status; and I want to do it for both dog and cat terms:
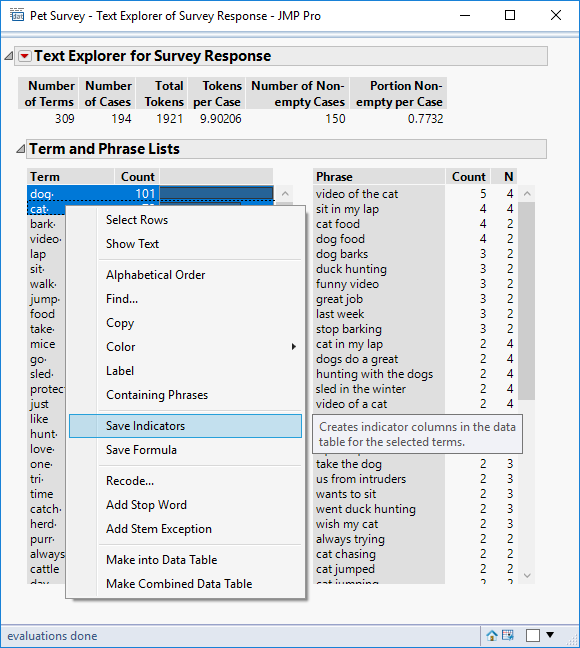
This generates indicator columns that can be used to filter and classify the data rows:
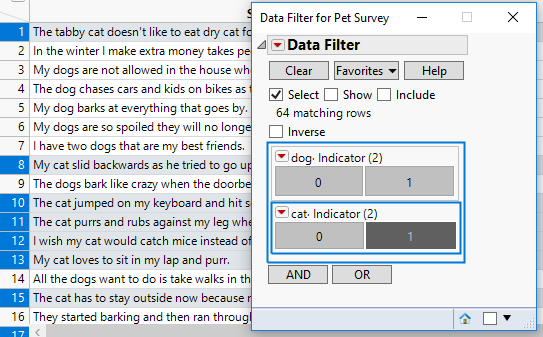
I would like to use the indicator to determine whether or not the respondent owns a dog or cat. I can use it that way but there will be a degree of misclassification. The indicator doesn’t know the context of the words – it’s simply an indication of whether a term appears in the body of text.
A stronger indication of ownership might be a phrase such as “my dog” or “our cat”.
Phrases
Most of the phrases relate to pet behaviour. That’s not surprising given the original question of the survey (“Think about your cat or dog. What’s the first thought that comes to mind?”). But I want to look for phrases that relate to ownership. In the data there are phrases such as “my cat …”; why is it that these phrases are not listed? The answer is stop words. Phrases are not listed if they start or end with stop words; “my” and “our” are both built-in stop words.
To exclude a built-in stop word I need to include it in the local exceptions list:
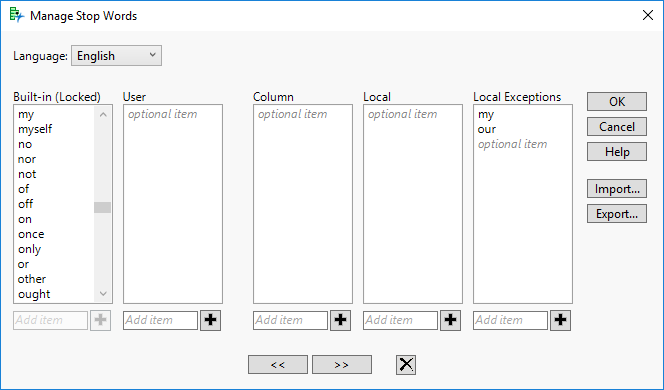
With these exceptions the most frequent phrases become “my cat” an “my dog”. Notice the high occurrence of the term “my”; on its own it’s not particularly informative hence the reason it is a built-in stop word.
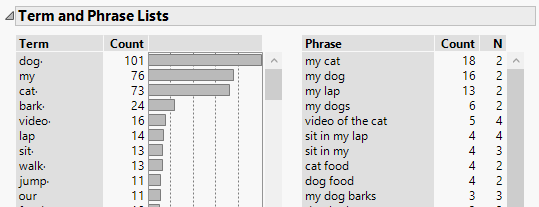
Just as with terms, I can right-click on phrases and save them as indicators. Whilst these indicators give me much less coverage of the data, they give me a very high degree of confidence that they indicate ownership of a particular type of pet.