It turns out that the prediction profiler has a hidden secret. And not just some easter egg feature that is just a bit of fun. This secret is core to how you use the profiler – and might just totally change how you use it in future.
Category Archives: Modelling
The Neuron
A neuron is a single node within a neural network. By analogy with neurons within the brain we can think of a neuron “firing” in response to an input trigger, and we can think of machine learning as the process of training the neuron to recognise that input trigger.
Prepping Data
Most of the work associated with building a predictive model is associated with either performance tuning or data prepping.
I’m almost half way through prepping some data. It’s not necessary to script this but a script allows me to adjust the data preparation in the future and more importantly to document the sequence of steps that I have taken.
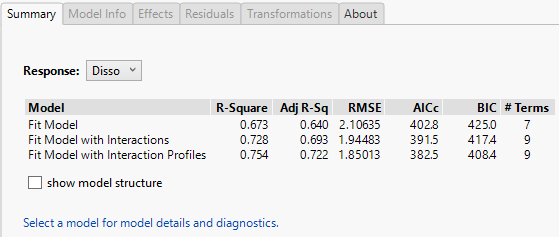
Segmented Regression
I’m sure there is a more technically correct term for this: I use the phrase segmented regression to describe the process whereby I select a segment of data within a curve and build a regression model for just that segment.
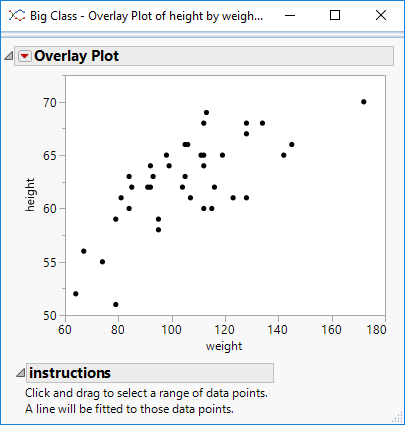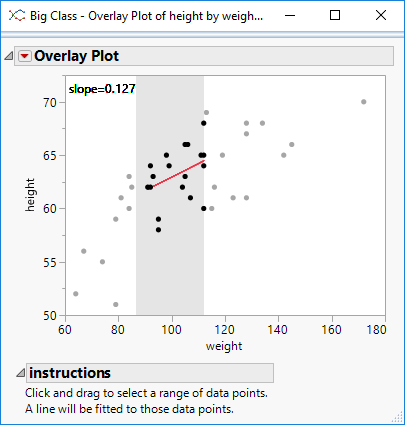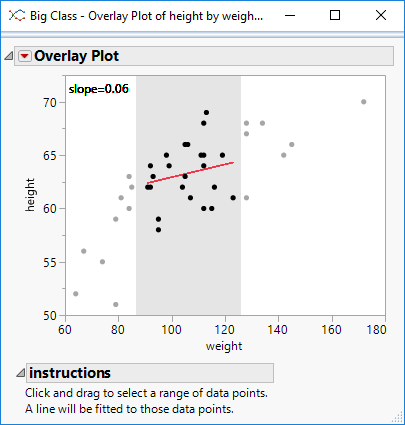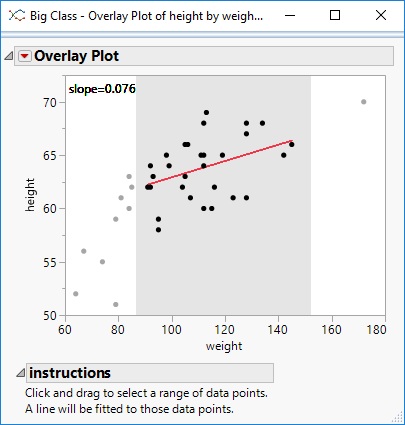
I have some code to aid the process. The code illustrates how to perform regression on-the-fly as well as how to utilise the MouseTrap function to handle mouse movement events.
Model Diagnostics Addin
A Trivial Neural Network
I have been investigating the use of logistic regression to model image pixel data. Now I want to take a look at the use of neural networks. In this post I am going to build the simplest possible neural network and compare it against a simple logistic regression.
Stepping Carefully
In this post I will continue with my so-called hieroglyphics project. This project uses a set of image data that describes handwritten characters. The dataset is frequently used to evaluate machine-learning algorithms. I’m using the dataset to explore a variety of modelling techniques within JMP.
In my last post I used a script to incrementally add terms to my model so that I could explore the performance of the model with increasing complexity. But the order in which I added the terms was based on a heuristic and it wasn’t necessarily optimal. So in this post I want to explore using stepwise regression.
Logistic Regression pt. 2
Logistic Regression pt.1
In a recent post I created a table that contained two classes of data: images that represent either the handwritten digit ‘5’ or the digit ‘6’. In this post I’ll model the data using logistic regression. I will also take the opportunity to look at the role of training and test datasets, and to highlight the distinction between testing and validation.
Box-Cox Transformation
Box-Cox transformations have always been a feature that has been tucked away under the red triangle options of Fit Model. In version 13 of JMP this functionality is brought to the foreground. It appears as default output when you choose the Effect Screening emphasis.
(more…)