It turns out that the prediction profiler has a hidden secret. And not just some easter egg feature that is just a bit of fun. This secret is core to how you use the profiler – and might just totally change how you use it in future.
Let’s say I construct a regression model using the Fit Model platform. The usual method to visualise the model is to use the prediction profiler available from within the platform.
If I want to visualise the model later (or perform post-modelling tasks such as simulation) then I can save the prediction formula as a column and access the Profiler platform directly from JMP’s graph menu.
The trouble is, plotting a formula gives you just that: the formula with no sense of goodness of fit.
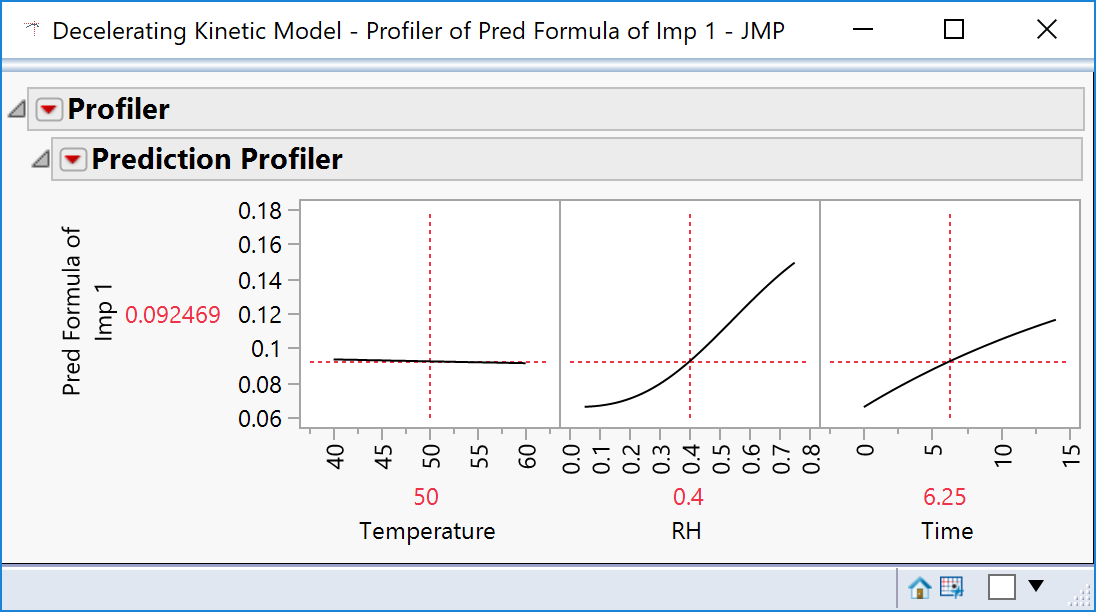
If you want to have confidence intervals on the curves then you have to use the profiler via the Fit Model platform.
Or so I thought – but it turns out that I was wrong.
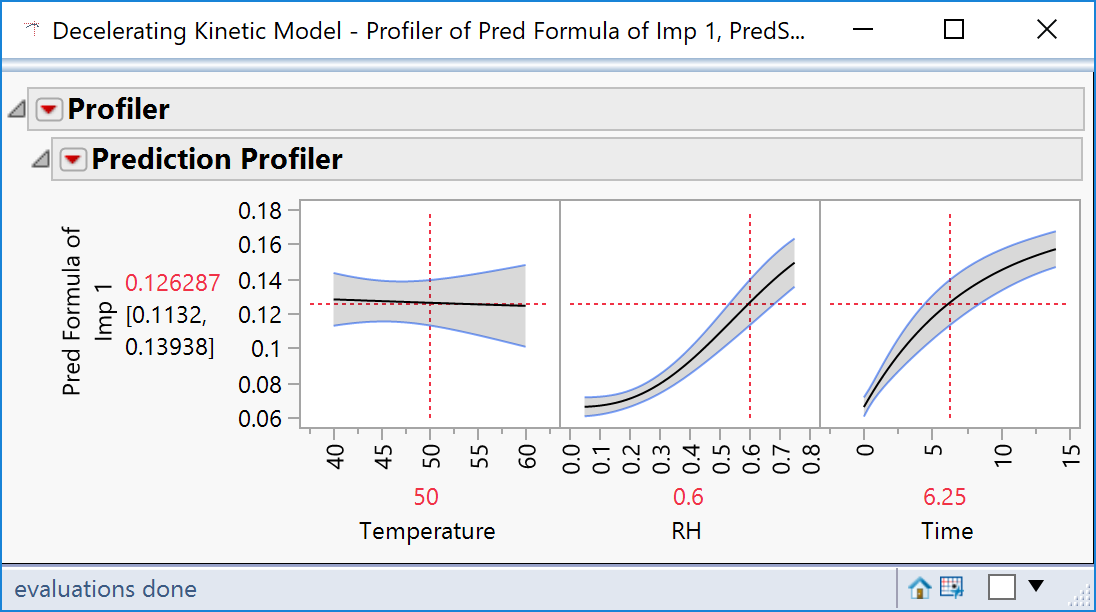
It is possible to include the confidence interval: perhaps I should have known how to do this, but I think it’s sufficiently obscure to warrant being classed as a hidden secret!
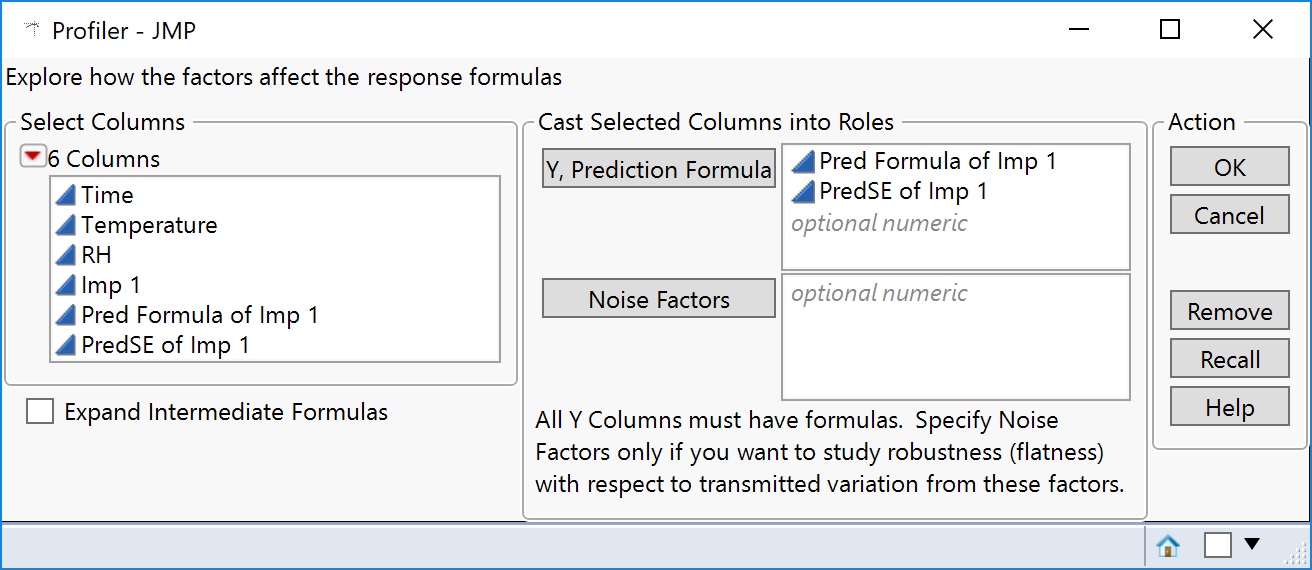
When you have the prediction formula there is also an option to save the formula for the standard error of prediction. So far so good. But there is no obvious way to tell the prediction profiler that it should use this formula column to compute the confidence intervals. But it will do it for you if you name the columns correctly.
- The model formula column must be named
“Pred Formula of <name>” - The formula for the standard error must be named
“PredSE of <name>”
<Name> can be anything (typically the name of the response being modelled). The rest of the wording must be exact, including the space between “Pred” and “Formula” and no space with “PredSE”.
Here is an example:
If you have done it correctly the following message appears:
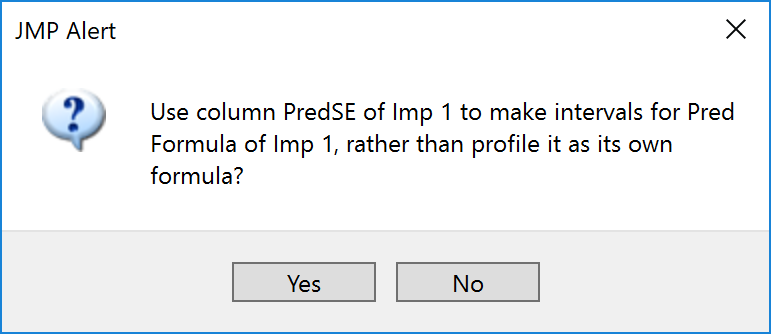
Click Yes and hey-presto!
David, I recently posted a question in the jmp community forum on how to save the predse in the generalized regression platform. To do just what you show here. Do you know if ithis is possible?
Thanks!
Matteo
Unfortunately I’m not aware of a way to do that. It’s frustrating that you can save the data values but not the formula.
To this point, I have posted a question on the JMP Community Forum which nobody seems to have any answer for (https://community.jmp.com/t5/Discussions/Profiler-discussion-continued/td-p/458245). At this point I think the feature you are pointing out is either extremely unique and valuable – or incorrect. Can you shed any light on this? Thanks.