In this post I will walk through some of the common tasks that are undertaken when we process unstructured text-based data. This will also give me the opportunity to introduce the terminology associated with text processing.
Introducing the Problem
For the purposes of illustration I will use the data table Pet Survey that can be found in the JMP sample data. This is a fictional set of data that contains responses to the following question:
“Think about your cat or dog. What’s the first thought that comes to mind?”
Here are some of the sample responses:

One of the most basic questions that I could ask of this data is whether the survey response refers to a dog or a cat. One way to answer this question would be to create a formula to look for key words:
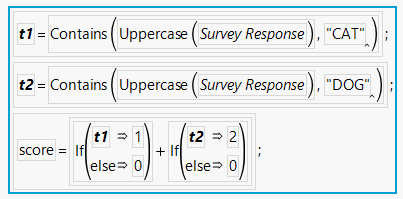
This formula generate a value of 1 if the response refers to a cat, 2 for a dog, 3 for both and 0 for neither:
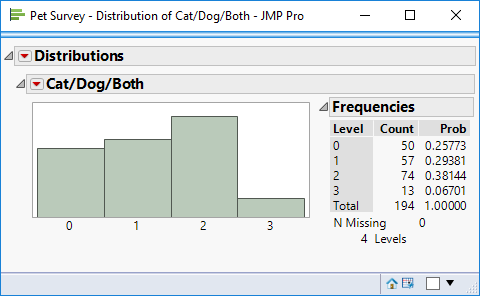 The histogram of the formula column indicates that 57 respondents refer to a cat whereas 74 refer to a dog. 13 of the respondents refer to both cat and dog, and 50 refer to neither.
The histogram of the formula column indicates that 57 respondents refer to a cat whereas 74 refer to a dog. 13 of the respondents refer to both cat and dog, and 50 refer to neither.
The formula is doing its job of helping me to classify the survey responses. But I should take a closer look to ensure that these classifications are working correctly. There are 50 respondents with a score of zero. Perhaps they have pets other than cat or dog?
Making a subset table for the 50 zero-score responses shows that for 44 cases there were no responses. The other 6 responses are shown below:

To deal with this data my column formula needs to be more sophisticated. I want a dog score when “huskies” are mentioned; and with the example in row 3 I want to infer a dog when “barking” occurs.
Already I am starting to see how processing of unstructured text data can become fiddly and rapidly degenerate into complex algorithms tailored to suit the specific text content.
Let’s take a look at a score of 3; this is intended to classify survey responses that refer to both cats and dogs:

There are two main problems. The first is that “cat” is being matched with non-pet words e.g. “cattle”. I could fix that by replacing the “Contains” test with a more sophisticated test that identified whole words. The second problem is one of context: I want to use the score to infer whether to respondent owns a cat or dog; in row 2 they own both, in row 12 they own a cat and in row 3 they have a dog. There are nuances to language that get ignored if I focus only on individual words.
Tokenization
Using a column formula I have tried to create a classification flag to indicate whether the survey responses refer to cats or dogs. Very quickly I have hit some problems, for example, I’m not distinguishing between “cat” and “cattle”. Consider the following sentence:
“The cat,dog and cattle all live happily together.”
When we read the sentence we automatically break the sentence down into individual words. These words are like atoms – they are the building blocks of our text-based information. From an IT perspective, the process of converting a sequence of text into these building blocks is known as tokenization; the building blocks are referred to as tokens.
So words and tokens are pretty much the same thing. But I’m not interested in all words. If I wanted to generate tokens for the above sentence I’d probably want to skip the words “the” and “and”. Words that are skipped are referred to as stop words. Conceptually I can think of performing tokenization to construct a dictionary of useful words: “cat”, “dog”, “cattle”, “live”, “happily”, “together”. The items in this dictionary are referred to as terms.
Here is the academic definition of a token and the distinction between a token and term:
“A token is an instance of a sequence of characters in some particular document that are grouped together as a useful semantic unit for processing. A type is the class of all tokens containing the same character sequence. A term is a type that is included in the systems dictionary.” (C.D.Manning et al, 2008).
Using JMP’s Text Explorer
Now let’s see how the text explorer can help to make sense of our text-based data. The text explorer is found on the analyze menu and presents the following dialog window:
Some of these options need some explanation. But they will be easier to understand once we’ve seen what JMP plans to do with our data:
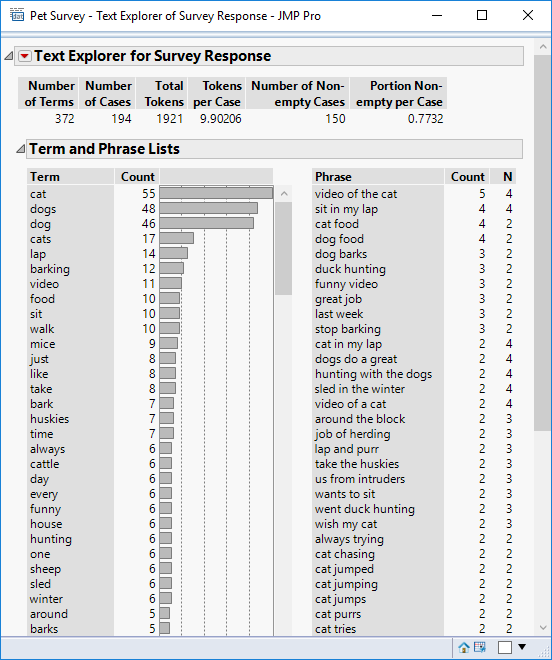 The platform identifies the occurrence of individual words (terms) and combinations of words (phrases).
The platform identifies the occurrence of individual words (terms) and combinations of words (phrases).
The data table consists of 194 rows, and within these rows 372 distinct words have been identified. On average each response contains 9.9 words. Of the 194 responses, 77% (150) were non-empty.
Let’s take a closer look at the two columns of output, and the underlying processing that is being performed.
Terms
The first task performed by JMP is to look for words. I did the same thing using the formula – looking for “cat” and “dog”. But JMP identifies all words and provides us with a sorted list based on frequency of occurrence.
A word is an example of a token. Each survey response is broken down into tokens and the tokens are counted. To aid this process the text is first converted to lowercase (I did the same thing with the column formula – except that I used uppercase – the intent was the same – to treat “cat” the same as “Cat”).
JMP offers two mechanisms for generating tokens:
Basic Words is the easiest to understand. When we look at a sentence we identify words because they are delimited by white space or punctuation marks. These are standard syntax rules for looking at the basic structure of a sentence of text.
Computer programmers often want to apply more complex syntax rules that are articulated as regular expressions (Regex). JMP uses a set of these rules by default. These expressions allow for more sophisticated handling or technical text such as dates, times and web content (hyperlinks and domain names). For the example data there is no difference in the results of the two methods.
By the end of this processing each survey response has been broken down into their component tokens (words).
Not all tokens are interesting. So next a list of “interesting” tokens is constructed. This is the list of terms shown in the JMP report. What is not interesting? So called stop words – common words such as “and” and “the”. JMP has a predefined list of stop-words – here are the ones starting with “a”:
- a
- about
- above
- after
- again
- against
- all
- am
- an
- and
- any
- are
- aren’t
- as
- at
Where can you find this list? How can you add or delete words from this list? These types of question I will deal with later when I discuss the workflow associated with text analysis.
The list of terms also takes account of stemming rules that may have been applied to the data. Stemming is the process of using a single term to represent multiple tokens all of which start with the same sequence of characters (the stem). For example, rather than have separate terms “cat” and “cats” I may want these tokens represented by a single term “cat”. By default stemming rules are not applied, so I will defer further discussion to my review of the text analysis workflow.
Phrases
A phrase is a sequence of words. JMP looks for recurrent phrases and lists them is descending order of frequency. “Video of the cat” is the most frequent phrase. The initial JMP dialog allows you to specify the maximum number of words in a phrase; the default is 4.
Using the Information
JMP has evidently created useful information from the unstructured data. I’ve identified instances of words such as “dog” and “cat” as well as relevant phrases such as “dog barks”.
But I could equally say that JMP has identified words that are not useful: “just”, “every”, “one” and phrases that I’m not interested in: “last week”, “great job”.
So I would still like to do more filtering of these non-interesting words. And how do I deal with the pesky case of huskies?
Also, having done all this fancy text processing, can I get to the point of answering a simple question such as “how many respondents own a dog and how many own a cat?”.
The answer to all these questions comes down to the workflow that we use to analysis our text data. The tools to support that workflow are found under the red triangle hotspot. These options include:
- Stem rules
- Recoding rules
- Managing stop words
- Managing phrases
I’ll discuss the workflow in a separate post.
References
Introduction to Information Retrieval,
C.D. Manning, P Raghavan, H Schütze
Cambridge University Press. 2008