 Zip files are a common file format for sharing collections of files or for compressing large files. I’m going to take a look at how JSL can be used to handle these files without first manually unzipping the file.
Zip files are a common file format for sharing collections of files or for compressing large files. I’m going to take a look at how JSL can be used to handle these files without first manually unzipping the file.
Tag Archives: Data Manipulation
Prepping Data
Most of the work associated with building a predictive model is associated with either performance tuning or data prepping.
I’m almost half way through prepping some data. It’s not necessary to script this but a script allows me to adjust the data preparation in the future and more importantly to document the sequence of steps that I have taken.
Scripting Table Subsets
The best way to script table manipulation tasks such as joins and subsets is to first perform the task interactively and then make a copy of the source JSL that is automatically generated by JMP. In many instances this code is sufficient, but sometimes you need to make the code more general, and that’s where things can get tricky.
In this post I will take you through the process of transforming the JMP-generated code into a more flexible piece of JSL.
Remove Empty Columns
It’s not Friday. But I’ve just written this function and I thought I’d share it. Plus it’s Christmas. Almost.
Some background: I’ve just loaded a spreadsheet into a JMP table and it contains 257 columns. Only 55 of the columns contain data. This function will zap the empty columns and make the table more manageable.
Inserting Columns
This is one of a series of posts highlighting new features available in version 13 of JMP.
As you discover the features new to version 13 you start to realise that a lot of work has been applied to enhancing workflow. You can perform the same tasks but with fewer steps.
(more…)
New Formula Editor
This is one of a series of posts highlighting new features available in version 13 of JMP.
The formula editor has had a big revamp. If you liked the old editor, don’t worry, it works the same way, but it has been re-designed to utilise screen space more efficiently and enhance the workflow.
Performance Trap
I was recently processing a number of files using pattern matching. During the processing I was storing information in lists which were subsequently used to populate new JMP data tables.
 Everything worked fine until I increased the number of files by a factor of 10.
Everything worked fine until I increased the number of files by a factor of 10.
After some time I started hitting ‘escape’ and ‘CTRL-Z’ in a frenetic effort to seize control of my laptop.
More Pattern Matching
In my last post I introduced the principles of using the pattern matching functions within JMP. Once you start using pattern matching you will discover that you need to use some additional features, which I discuss here. (more…)
Basic Pattern Matching
Pattern matching is an incredibly powerful technique for interrogating text strings for the purpose of matching and manipulating string patterns. In this post I will illustrate some of the basic principles of pattern matching. This will be followed by more advanced scenarios. (more…)
Linearly Separable Data
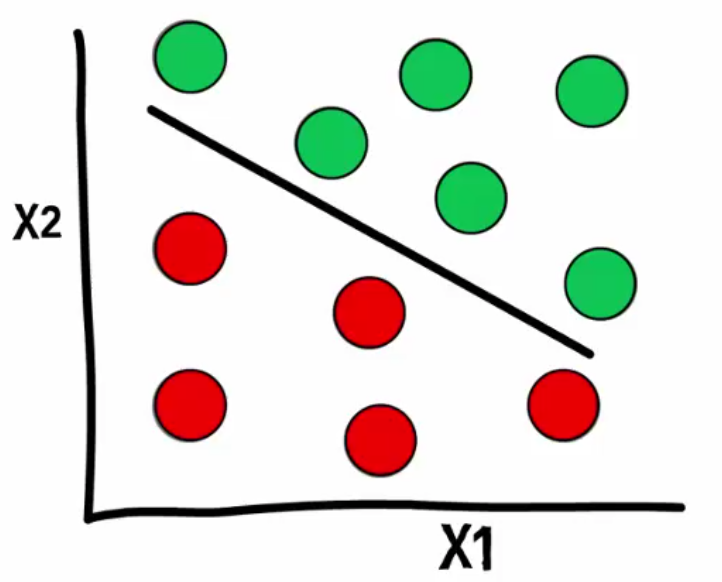 In my last post I outlined some “homework” that I had set myself – to write a script that would create linearly separable data. I want the ability to create it in an interactive environment. (more…)
In my last post I outlined some “homework” that I had set myself – to write a script that would create linearly separable data. I want the ability to create it in an interactive environment. (more…)