Here is a data table that I have created. It happens to contain data
that is the result of a designed experiment. I know that, but JMP doesn’t.
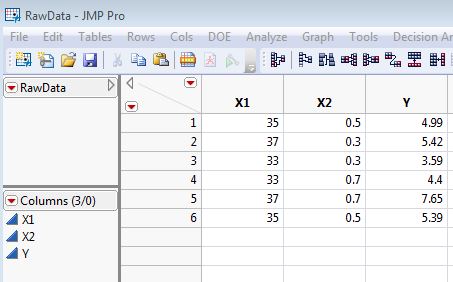
Below is the output from the Fit Model platform based on a model with terms for the main effects and the two-factor interaction:
Notice that the interaction term in the parameter estimates is shown as:
(X1 – 35)*(X2 – 0.5)
The numbers 35 and 0.5 represent the means of the respective variables. By default JMP performs this so-called centre-scaling, which is a common practice when building regression models that involve interactions or other high-order terms.
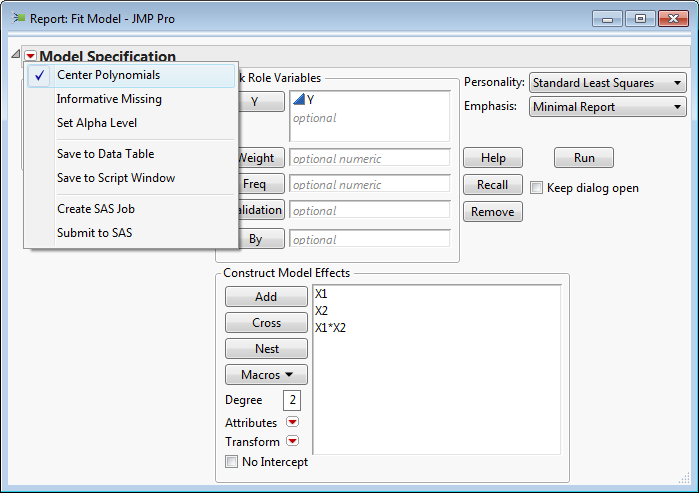
The option to control centre-scaling is hidden away in the red triangle hotspot of the model specification window:
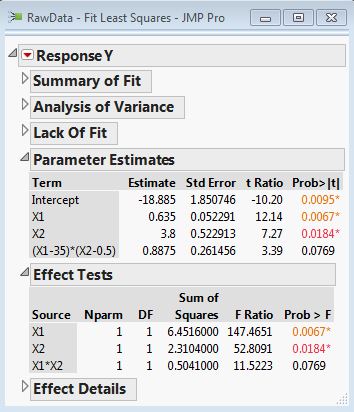
The benefit of centre-scaling is that it produces more reliable estimates of p-values:
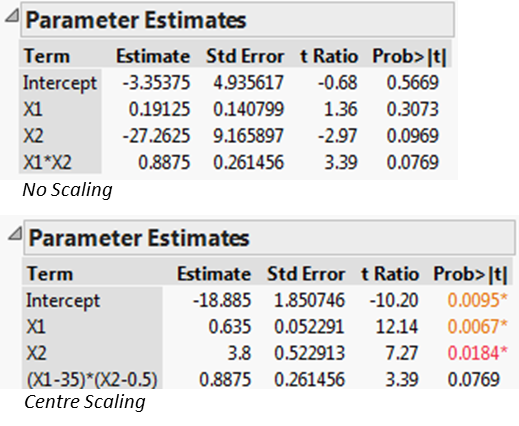
In particular, if we don’t scale, then the addition of the interaction term causes a bias in the estimates of the standard errors of the main effects, causing them to be inflated. The result in the above example is that the main effects appear to not be statistically significant (even though they are if the interaction term is absent).
Centre scaling is therefore strongly recommended particularly when variables have very different scales (X1 is 100 times the magnitude of X2). Unfortunately it makes the notation somewhat cumbersome. A cleaner notation is found in the Effect Test Outline where the interaction is listed without any explicit reference to the centre scaling.
If we had created a DOE in JMP then the modelling behaviour is subtlety different:

The model for a DOE is based on an orthogonal scaling of the variables. This scaling is based on the range of the variables and transforms them to act in a range -1 to +1. So in the model both X1 and X2 have a range -1 to +1. To indicate the actual range, it is shown in parentheses of the main effect names e.g.
X1(35,27)
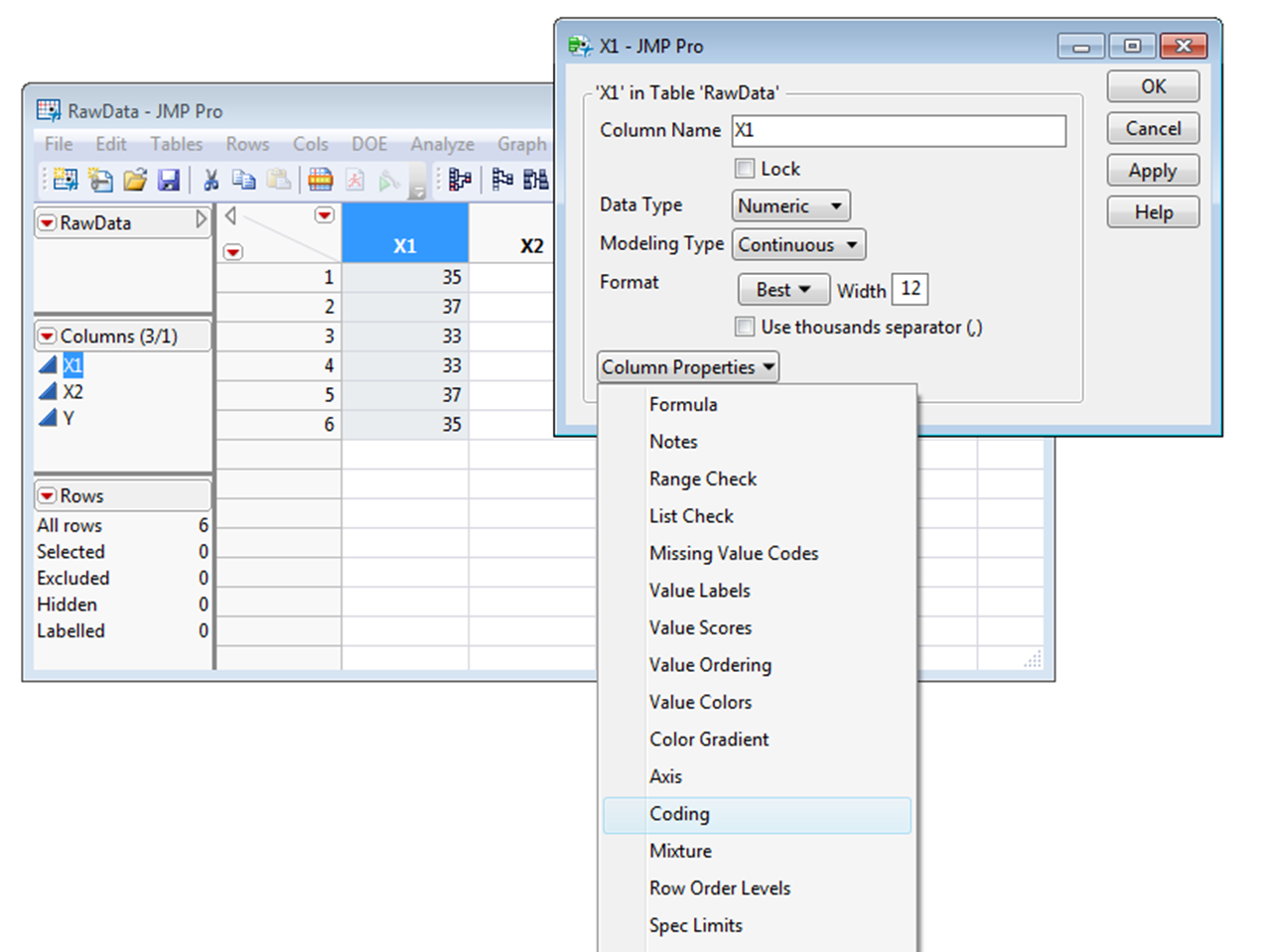
This orthogonal coding of the variables is a property of the table column which is automatically set when I create a designed experiment in JMP:
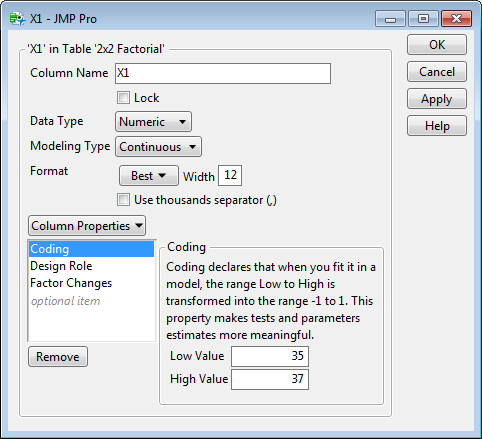
If I have historical data which we know is from a DOE then I can manually set the coding property of the column:
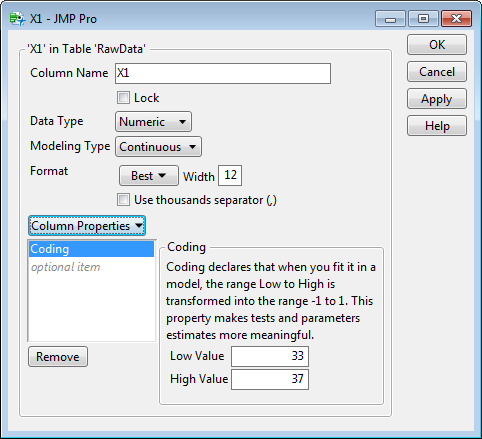
JMP will automatically assign the codes according the range of the data:
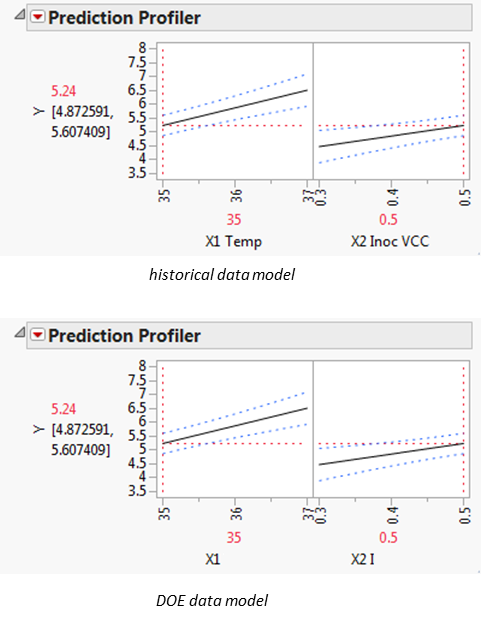
The purpose of scaling is to give the best possible statistical assessment of the model. In terms of interpreting the model, the JMP Profiler will always show the natural scale of the variables:
Merely needed to emphasize Now i’m delighted that i came upon your website.
Bro, u saved my life.
I found such values in the terms of my parameter estimates when analysing my full factorial design. Search al over the internet, yet could find’t the answer. i’m defintly going to explore this website in depth. thanks for the help!
Max
Excellent explanation for me since i got confused of those interaction terms. Really thanks. May I ask does that mean it’s going to be better to always use this centre scaling in DOE and modeling? Any case could have adverse effece due to centre scaling? Thanks.
JMP will always apply appropriate scaling to data automatically – centre scaling for so-called happenstance data, and orthogonal scaling for DOEs: you don’t have to make a conscious decision to apply this scaling – the reason for the post was to explain the nomenclature that this gives rise to when looking at parameter tables.
There is no adverse effect of applying this scaling other than misinterpreting the parameter estimates (i.e. it is the coefficient of the scaled value of ‘X’, not ‘X’ itself. The prediction profiler helps ensure we interpret the numerical outcomes correctly.
Thank you very much for details.