A column of a JMP table acts as the primary source of data for most types of analysis within JMP. That is evident by the fact that the first task you perform when you launch a platform is to assign columns to roles:
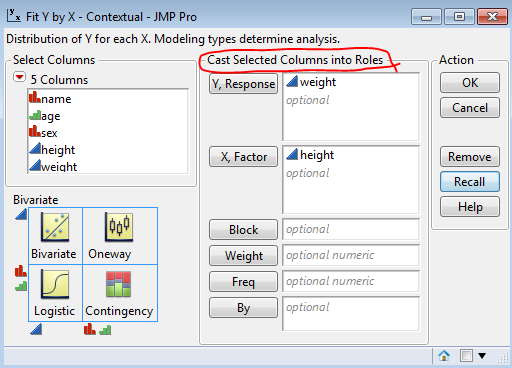
The output for this column specification is a bivariate plot:
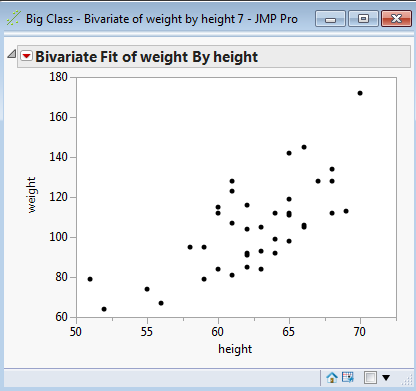
If you want to re-create this output in the future then you can save the associated script:
Bivariate( Y( :weight ), X( :height ) );
Notice that the script contains the columns assignments that have been performed, namely the association of the columns weight and height to the Y and X axes respectively.
The script contains an intuitive notation for the column specifications. If you wanted to change the script to create a graph of weight versus age you could just replace height with age:
Bivariate( Y( :weight ), X( :age) );
In these examples :weight, :height and :age are known as column variables. They are unique to JMP and make it very easy to create scripts to replay a particular form of analysis. But they are somewhat tricky if we want to apply programming principles to the code in order to make it more general.
What exactly is :weight? It is a reference to the column weight in the current data table. We know it is a column reference because of the colon notation.
A column is a collection of information which in programming terms is referred to as an object. The most obvious information associated with the column is its name and data. If I wanted to retrieve all the data values associated with the column I can send a message to the column:
weightValues = :weight << Get Values;
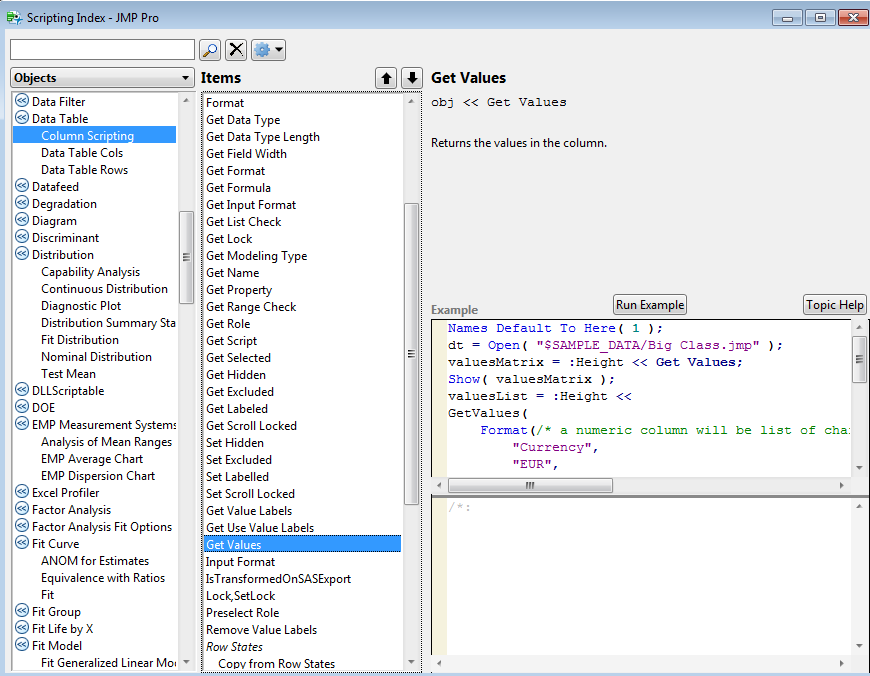
If you are familiar with programming, this is the equivalent of using an object method. You can find a full list of the messages that can be applied to a column in the scripting index (Help menu):
Often in programming we want to take specific code and make it more general. It maybe that instead of taking the column “weight” I want to take the first column of the table (independent of its name). To do this I need to construct my own variable which will reference the column:
firstCol = Column(1);
What is the name of this column? I don’t know, it depends on which table is open, but if I wanted to find out I could send a mesage to the column:
colName = firstCol << Get Name;
Conversely if I know the column name but not the position within the table then I could create a column reference like this:
weightCol = Column(“weight”);
This might seem a bit perverse. If I know the column name why not use the default notation :weight? As I said earlier, we often want to make code more general and to do this we need to use generalised variables.
Let’s say that I have a list of column names:
lst = {"age","height","weight"};
then using column variables I can iteratively perform tasks for each column within the list:
lst = {"age","height","weight"};
For (i=1,i<=NItems(lst),i++,
colName = lst[i];
col = Column(colName);
// do something interesting here
);
For each iteration of the loop the variable col references a different column of the current data table. For illustration purposes I have created a hard-coded list of column names but usually the list would be derived from a user interface selection of columns or by performing a query on the data table; for example the code below will give me a list of column names that have a data type of numeric:
dt = Current Data Table(); lst = dt << Get Column Names(string,numeric);
In the example of the for-loop above, I put an annotation “do something useful here”. What could I do? Perhaps I want to create multiple bivariate plots, all with weight on the y-axis but each with a different variable on the x-axis.
To do this I want to first put the bivariate code inside the for-loop and then replace reference to the height column with my own column reference variable:
dt = Current Data Table();
lst = dt << Get Column Names(string,numeric);
For (i=1,i<=NItems(lst),i++,
colName = lst[i];
col = Column(colName);
Bivariate( Y( :weight ), X( col ) );
);
I’ll leave it as an exercise for the reader to modify the code so that the redundant graph of weight versus weight is not produced!
Sometimes the auto-generated code that is produced by JMP will look different and it’s possible for you to follow the above logical sequence and end up with code that doesn’t work. So let’s look at why this happens.
JMP is very flexible in the naming conventions of columns. It allows you to have multiple-worded names, and to use names that contain a variety of symbols. This can become problemmatic at the coding level. Consider the following portion of code:
answer = :height / inches;
What is it doing? Maybe converting height from units of feet to units of inches? Or maybe the column name is “height / inches”!
Let’s say we change the name of our column from “height” to “height / inches”.
In the first instance the associated JMP generated column reference is :height.
In the second instancve the associated JMP generated column reference is :Name(“height / inches”)
Notice two things. The colon is replaced with :Name, and the name of the column is now a quoted string.
The JMP generated code for the bivariate graph now looks like this (I have split the code across multiple lines to increase legibility):
Bivariate(
Y( :weight ),
X( :Name( "height / inches" ) )
);
When we put this into the for-loop it we will want to replace the text string of the column name with a string variable like so:
dt = Current Data Table();
lst = dt << Get Column Names(string,numeric);
For (i=1,i<=NItems(lst),i++,
colName = lst[i];
col = Column(colName);
Bivariate(
Y( :weight ),
X( :Name( colName ) )
)
);
However, this doesn’t work. The :Name notation requires an explicit text string. There are ways to achieve this but that would be a lengthy description. However, we don’t need the :Name notation because we are not trying to create a variable with the same name as the column. So we just need X( col ) as in the original example.
As a side-note it is sometimes more convenient to work with column names instead of column references. If for the x-axis specification I want to use the colName variable (which is just the name of the column – a text string, not a column reference) then I can do so using the following notation (note the use of the Eval function):
dt = Current Data Table();
lst = dt << Get Column Names(string,numeric);
For (i=1,i<=NItems(lst),i++,
colName = lst[i];
Bivariate(
Y( :weight ),
X( Eval(colName) )
)
);
That should cover everything shouldn’t it? Actually no. There is one more complexity. When you save a script associated with a platform it contains not only the original column associations but also details of any other edits that have been performed. Let’s say that we change the font styles of the axes:
Bivariate(
Y( :weight ),
X( :height ),
SendToReport(
Dispatch(
{}, "weight", TextEditBox,
{Set Font Style( "Bold" )}
),
Dispatch(
{}, "height", TextEditBox,
{Set Font Style( "Bold" )} )
)
);
You may have noticed that edits create far larger scripts! And embedded within that extra code are additional references to column names. These references also need to be replaced when we generalise the code to use variables.
If we are going to put this new code in our for-loop, again we need to replace :height with a column reference, but we also need to replace the text string “height” with the string variable colName:
dt = Current Data Table();
lst = dt << Get Column Names(string,numeric);
For (i=1,i<=NItems(lst),i++,
colName = lst[i];
col = Column(colName);
Bivariate(
Y( :weight ),
X( col ),
SendToReport(
Dispatch(
{}, "weight", TextEditBox,
{Set Font Style( "Bold" )}
),
Dispatch(
{}, colName, TextEditBox,
{Set Font Style( "Bold" )} )
)
)
);
Nice idea, but it doesn’t work. The variable colName is not achieving the desired result of changing the x-axis font to bold. Earlier I illustrated a trick that used the Eval() function, but that doesn’t work either.
So what do we do?
There are three possible solutions to this problem, and they will be the theme of my next blog update.
I love browsing your website. With thanks!
There should be one consistent way to do things. JSL is notoriously bad for that.
Agree. Suffering from those tricks the computer scientists at SAS play.
This continues to be a very popular blog post – I’ll try and give it a refresh for the new year!
Finally, I am able to understand what is written here. Very useful. Thank you for laying it down so clearly. (Initially, I was of course hampered by a total absence of coding experience.)
Thanks for your positive feedback!