Note from author: this remains one of the most popular posts on this blog – so I have written an update.
A number of platforms in JMP allow for a variable number of columns. I want to take a look at how to handle this situation using the JMP scripting language.
Here is an example JMP generated script for the multivariate platform:

Notice that the Y columns are enumerated one by one. From a programming perspective this is not particularly convenient. Often I will have a list of columns that has been specified by a user. Let’s quickly take a look at that process:

This produces the following window:

When a selection is made the variable lstColNames is populated, for example:
lstColNames = {"Sepal length", "Sepal width"};
Notice that the list is a list of column names. If I want to convert them to column references I could do the following:
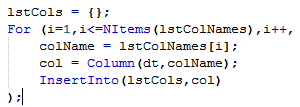
What’s the difference? A column reference is a reference to a column object for which JMP uses the colon syntax e.g. :Length whereas a column name is a simple text string “Length”;
Returning to the code for the Multivariate platform there is a line that reads:
Y( :Sepal length, :Sepal width, :Petal length )
I would like to replace this with the following:
Y( lstCols )
Now this is totally flexible. I don’t need to know in advance which columns, or how many. Unfortunately it doesn’t work. If you run the code and look in the log window the following error message is displayed:
Not Found in access or evaluation of 'Multivariate' , Bad Argument( {lstCols, Role requires at least 1 columns.} ), Multivariate( /*###*/Y( lstCols ) )
JMP is unhappy with the use of the lstCols variable. At the point of evaluating the code JMP doesn’t know what lstCols contains so we need to force the evaluation of the variable by using the Eval() function:
Y( Eval(lstCols) )
This works. In fact it also works if we use the original list of column names without having to convert them to column references. So here is the final code:
So let’s take this knowledge and apply it to a different platform. Here is the JMP generated code for the distribution platform:

Instead of having separate lines of code for each column we again want to use a more general piece of code based on the variable lstColNames. From what we have learnt we could try following syntax:

This doesn’t work correctly. Only the distribution of the first column in the list is produced. Time to check the online help! An essential resource for JSL is the Scripting Index under the Help menu. This is organised by the following classifications: functions, objects and display boxes. All the graphical and analysis platforms in JMP are objects. Here is the entry for the Distribution platform:
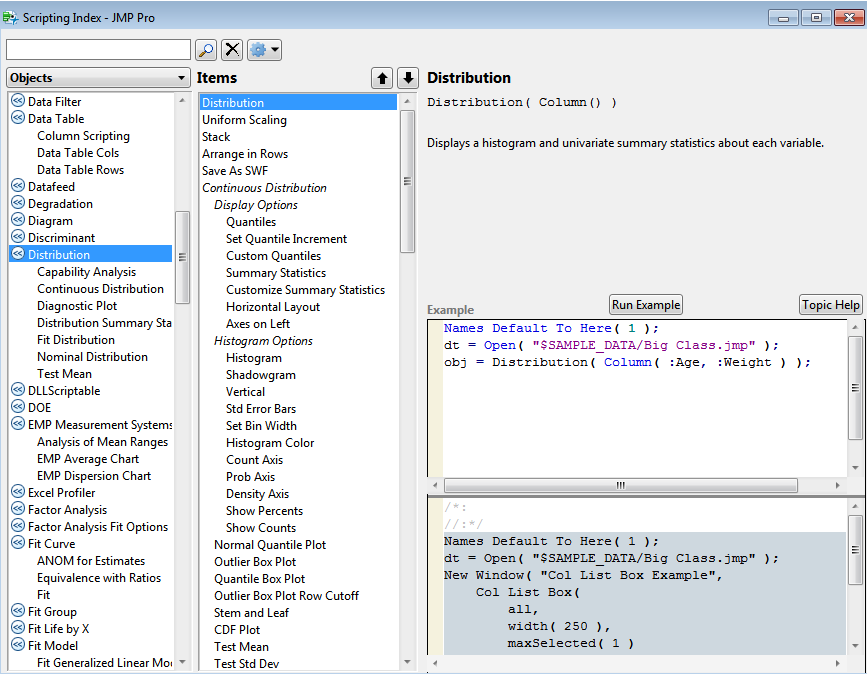
Conveniently it offers an example which has a subtle difference to the JMP generated code:
![]()
Based on this we can write:
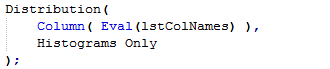
This works and as before the list can contain either column names or column references.
Now let’s take a look at the Graph Builder platform.
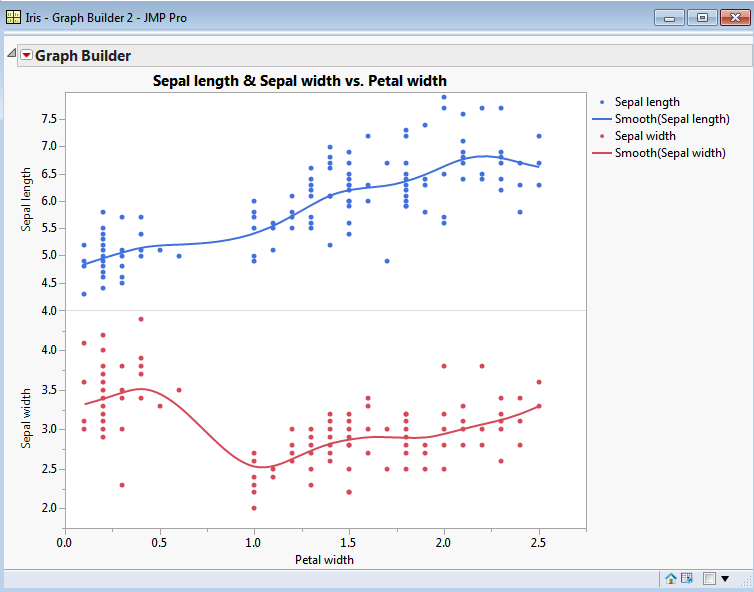
The above graph has two columns assigned to the y-axis. Here is the JMP generated code (reduced to the bare essentials):
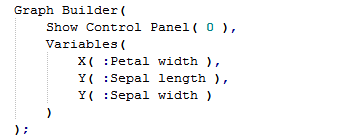
Applying the same rules as before we would like to write the following:
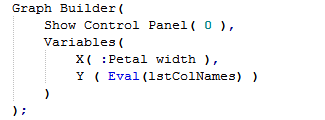
Whilst this code runs, it creates a graph with only one y-variable, corresponding to the first column in the list.
The problem gets worse. If I wanted a slightly different graph:
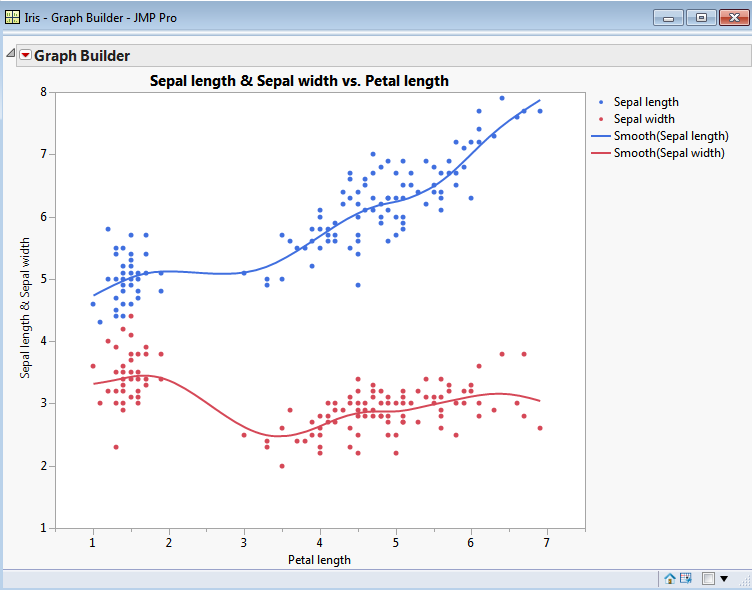
Then the specification for the Y columns becomes more complex – we see that it contains not only column references but also information relating to the positional format:
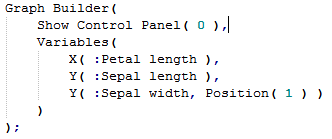
It looks like we need another way to construct this.
Take a deep breath. There is a method that is guaranteed to work, but it involves extra work.
The principle is this: we’re going to construct the exact code that JMP wants, so if we have selected 3 variables then the code will look like:

I’m also going to note that if the first Y column also had a Position(1) specification the code works fine, that is, I can write:

This at least gives me some consistency in the format I need for the Y columns.
OK, so how do I generate this code? The trick is to pretend that the above JSL statement is a simple text string. The goal is to construct this text using string manipulation techniques and finally execute the text as a JSL statement.
That probably needs some explanation. Here is one, by way of a simple example. Lets take a very simple JSL statement:
x = Log(20);
By analogy, we want to replace the hard-coded number 20 with a variable:
x = Log(y);
But we want to do this using string manipulation methods. So if we treat the above JSL statement as a text string then it looks like this:
"x = Log(y)"
And I can construct this string using string concatenation methods:
"x = Log(" || Char(y) || ")"
It’s convenient to store this in a variable (and a the same time I’ll make the y variable more explicit):
y = 20;
str = "x = Log(" || Char(y) || ")";
The colouring in the JMP script editor helps to see the separation of components:
![]() The variable str is a text string representation of a JSL expression. The process of converting text to computer code is referred to as parsing. Using the Parse() function I convert the text to a JSL expression:
The variable str is a text string representation of a JSL expression. The process of converting text to computer code is referred to as parsing. Using the Parse() function I convert the text to a JSL expression:
jsl = Parse(str);
Now that I have a JSL expression I can evaluate it i.e. execute it as if I had written the text directly as a JSL expression:
Eval(jsl);
Here is the full sequence with some illustrative log window output:

str = "x = Log(20)"; jsl = x = Log(20); x = 2.99573227355399;
This is an illustration of the process. Because I have applied it to a simple problem you will have the impression that it is making simple things complicated. The reality is that it makes very difficult problems solvable. Soon I want to apply this principle to the problem we are trying to solve – but first I need to introduce one last component to the solution.
Simple text sequences can be constructed through a process of concatenation:
str = "x = Log(" || Char(y) || ")";
But this gets tedious and error prone if there is a lot of text with many variable substitutions. Fortunately there are a couple of other methods that can be used. The first is to use text substitution, using the SubstituteInto() function. The second is to use the EvalInsert() function; this is my favourite method:
str = EvalInsert( "x = Log(^y^)" );
Using this function I simply take the original text string “x = Log(y)” and wherever I have a variable that I want to substitute (in this case the variable y) I “quote” it with the character ^.
Now I want to create a text string that has the following format:
Y ( :Sepal width, Position(1) ),
and I want to create one of these for each of the columns names in a list.

As I go through creating these strings I wan to combine them together into a single string (str):

Finally I am in a position where I can construct my desired Graph Builder code. I’m going to use this template where str is the text string that has been constructed to contain the specifications of the Y variables:
Graph Builder(
Show Control Panel( 0 ),
Variables(
X( :Petal width ),
str
)
)
The string variable is substituted using the EvalInsert() function:
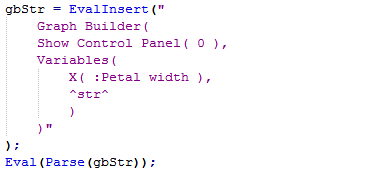
So the final code looks like this:

I am not a coder so this is beyond me. I have a list of column names that I would like to enter into table – subset – subset by name contain window. However this window only take one name and not a list of names. Is there a work around this or could JMP create this option?
I’ll create a post for you to explain how to do this
Weirdly, when I use your example it works perfectly. When I use one of my own, using a list of columns like:
s = dt << Get Column NAmes();
gblist = {};
For(q=1,q<=N Items(s),q++,
If(left(s[q],4) == "BEOL", Insert into(gblist, s[q]))
);
str="";
for(i=1,i<=N Items(gblist ),i++,
colName = gblist [i];
yStr = EVALINSERT("Y(^colName^, Position(1)),");
str = str||yStr;
);
This errors our on yStr = … with error
Name Unresolved: BEOL_ro_12 in access or evaluation of 'BEOL_ro_12 ' , BEOL_ro_12 /*###*/
where BEOL_ro_12 is the first column name in the list which looks like gblist={BEOL_ro_12 ,BEOL_rry_19,BEOL_p_1}
In my example the list of column names comes from a user selection and the list is a list of column names as STRINGS. In your example the column names are not strings but column references. So I think using s = dt << Get Column Names(String) should fix the problem for you. The yStr line is causing an error because you are doing a string manipulation on something that is not a string.
Note also that my example contains a colon before ^colName^
yStr = EvalInsert( “Y(:^colName^,Position(1)),”);
Try s = dt << Get Column Names(String); I'll have a play around and perhaps post an update to this code example!
Thanks for the great blog. It would be really helpful if the code was in text format, not in png so that it could be copied directly into the scripting window.
You are right – you will see that my more recent posts are in a text format that makes it easier to copy!
Thank you again for your posts packed with information. Immediately helpful!